





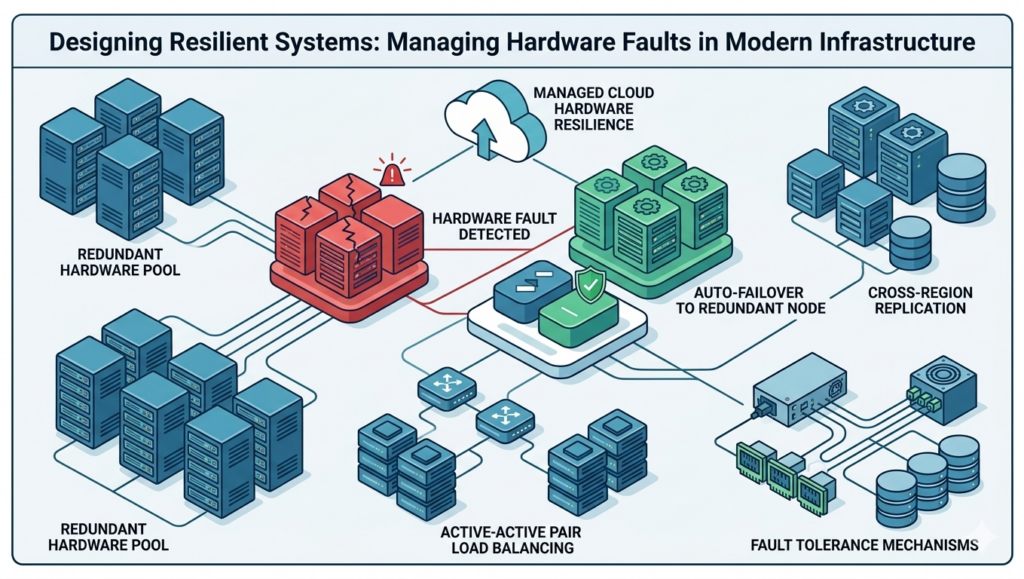
Hardware faults in distributed systems remain one of the most fundamental and unavoidable causes of system failure in modern software engineering. Physical components no matter how advanced are inherently prone to degradation and unexpected breakdowns. Hard drives fail, memory modules become unreliable, power outages occur, and network disruptions can arise from something as simple as a disconnected cable.
In large-scale environments such as data centers, these incidents are not rare exceptions but routine operational realities that must be anticipated, monitored, and effectively managed. Understanding hardware faults in distributed systems is essential for building reliable and scalable infrastructure.
What Are Hardware Faults in Distributed Systems?
Hardware faults occur when physical components deviate from expected behavior, leading to potential disruptions in system performance. In distributed systems, where multiple machines work together, even a single hardware failure can impact overall system reliability if not properly handled.
The Role of Hardware Redundancy in System Reliability
Traditionally, system reliability has been improved through
hardware redundancy
Components such as disks are configured using RAID (Redundant Array of Independent Disks), servers are equipped with dual power supplies, and backup energy sources like batteries and generators are deployed to ensure continuity during outages.
These measures are designed to eliminate single points of failure, allowing systems to continue operating seamlessly even when individual components fail. For many years, this approach proved sufficient, particularly when applications were hosted on a limited number of machines and failure rates were relatively low.
Why Hardware Failures Are Inevitable at Scale
However, as modern applications scale to handle massive data volumes and global user bases, the limitations of hardware-only redundancy have become increasingly evident.
For instance, even with a mean time to failure (MTTF) of several years per disk, a system with thousands of disks will experience frequent failures simply due to scale. In such environments, hardware failure is no longer an anomaly-it is an expected event.
Designing systems under the assumption that “everything will eventually fail” has therefore become a core principle of modern distributed computing and system design.
Cloud Computing and Unpredictable Infrastructure
This shift is even more pronounced in cloud computing environments, such as
Amazon Web Services (AWS)
where infrastructure is optimized for flexibility, scalability, and cost efficiency rather than guaranteed single-machine reliability.
Virtual machines may become unavailable without warning, and resources are dynamically allocated and deallocated. As a result, applications must be designed to operate reliably despite the unpredictable nature of the underlying hardware.
Software-Driven Fault Tolerance: The Modern Approach
To address these challenges, there has been a significant move toward
software-driven fault tolerance
Instead of relying solely on hardware resilience, modern systems are architected to tolerate the failure of entire machines.
Key Strategies Include:
- Distributed architectures: Spreading workloads across multiple nodes to avoid dependency on a single machine
- Data replication: Maintaining copies of data across different servers or regions
- Automatic failover: Redirecting traffic to healthy nodes when failures occur
- Rolling updates: Applying patches and updates incrementally without system-wide downtime
- Observability and monitoring: Detecting and responding to failures in real time
These strategies are critical for improving system reliability, scalability, and availability in modern cloud-native environments.
Operational Advantages of Fault-Tolerant Systems
These approaches not only improve resilience but also enhance operational efficiency. Systems designed for failure tolerance can undergo maintenance, updates, or scaling operations without disrupting users,something that is difficult to achieve in traditional single-server setups.
Organizations that adopt these practices are better positioned to deliver consistent performance, reduce downtime, and maintain user trust.
Designing for Failure, Building for Reliability
Ultimately, the key message is clear:
hardware will fail, but systems do not have to
By embracing failure as a normal condition and designing systems that can adapt, recover, and continue operating, organizations can build robust, scalable, and highly available applications.
Reliability, in today’s context, is not about preventing failure entirely-it is about ensuring continuity in spite of it.










{kind=link}