





The Internet is one of the most remarkable engineering achievements in history—so seamlessly integrated into daily life that many perceive it as a natural utility rather than a human-made system. This level of reliability and scale sets a high benchmark for modern technology.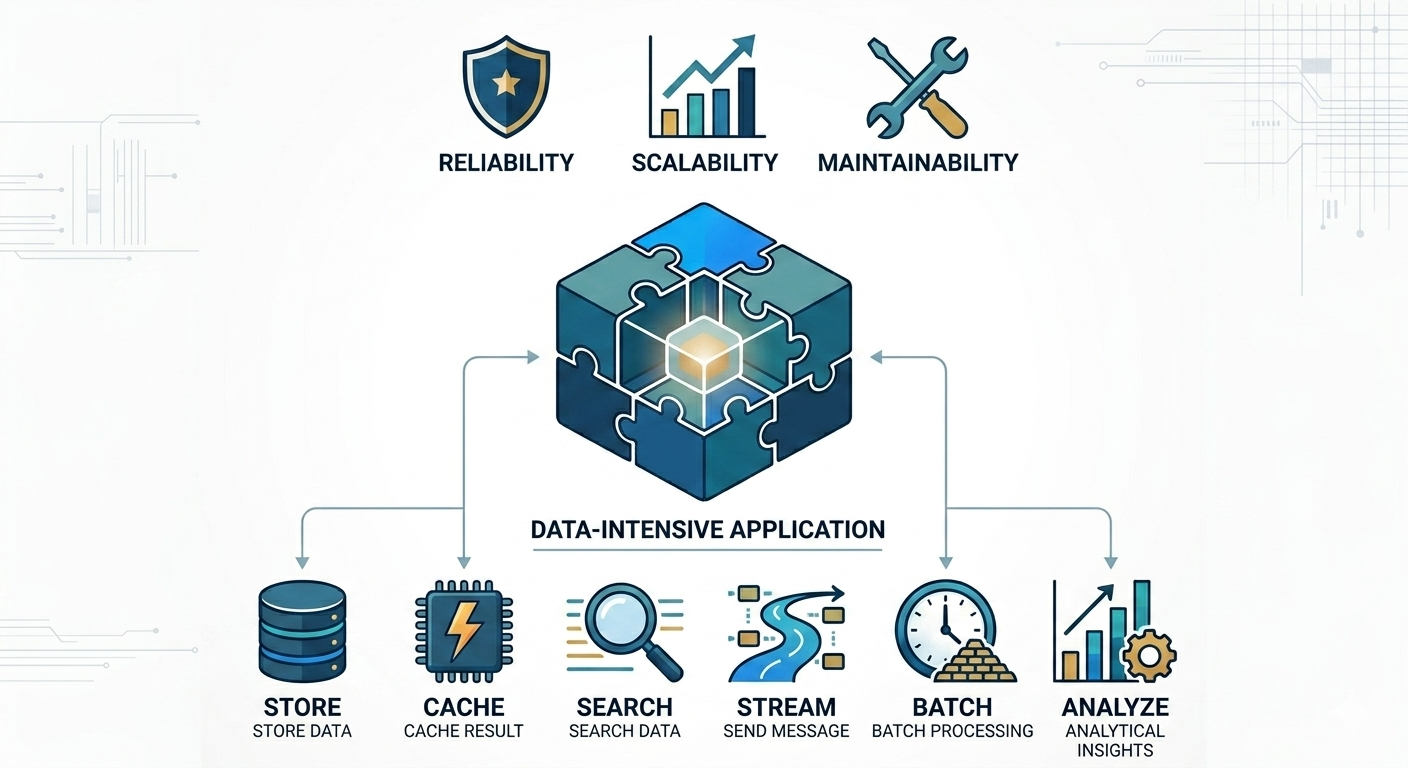
Today’s digital landscape is increasingly shaped by data-intensive applications rather than purely compute-driven systems. In most cases, processing power is no longer the primary constraint. Instead, organizations are challenged by the volume of data, its growing complexity, and the speed at which it is generated and must be processed.
To address these demands, modern applications are built on a set of foundational system components that provide essential capabilities:
- Data Storage Systems ensure that information is reliably persisted and retrievable when needed.
- Caching Mechanisms improve performance by storing frequently accessed or computationally expensive results.
- Search and Indexing Solutions enable efficient data discovery and filtering across large datasets.
- Stream Processing Systems support real-time data flow and asynchronous communication between services.
- Batch Processing Frameworks handle large-scale data analysis and transformations over time.
These components have become so standardized and effective that they are often taken for granted. Engineers rarely build such systems from scratch; instead, they rely on proven technologies that abstract away much of the underlying complexity.
However, selecting and integrating these tools is far from trivial. Each system comes with its own strengths, trade-offs, and operational considerations. Different applications have different requirements, which means there is no universal solution. Designing an effective data system often involves carefully combining multiple technologies to achieve the desired balance of performance, scalability, and reliability.
Understanding these trade-offs—and knowing how to align technology choices with business needs—is a critical skill in modern software engineering.
This discussion forms the foundation for exploring how data systems are designed and implemented in practice. At its core, the goal is to build systems that are:
- Reliable — consistently delivering accurate results even in the presence of failures
- Scalable — capable of handling growth in data, users, and complexity
- Maintainable — adaptable to change while remaining understandable and manageable
By examining both the principles and practical considerations behind these systems, we gain the insight needed to design robust, future-ready applications. Subsequent discussions will build on this foundation, exploring key architectural decisions and patterns that define successful data-driven systems.










{kind=link}