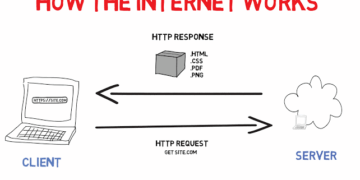





Figure1
Data models are one of the most important foundations of software engineering because they shape not only how software is built, but also how engineers think about the problems they are trying to solve.
Every application relies on some form of data representation. Whether building a social media platform, banking application, e commerce system, or AI powered product, developers must decide how information will be structured, stored, queried, and manipulated. These decisions influence scalability, maintainability, performance, and even the flexibility of the entire system over time.
A well designed data model makes software easier to understand and evolve. A poor data model can introduce unnecessary complexity, limit scalability, and create long term maintenance challenges that become increasingly difficult to fix.
How Software Systems Use Layers of Data Models
Most modern applications are built by layering one data model on top of another. Each layer abstracts the complexity beneath it and presents a simpler, cleaner representation to the layer above.
At every layer, the key question becomes:
How is this information represented in terms of the next lower level?
This layered approach is one of the core principles that makes modern software systems manageable despite their enormous complexity.
Layer 1: Modeling the Real World
At the highest level, application developers model real world entities and behaviors.
These may include:
- People
- Organizations
- Financial transactions
- Products and inventory
- Sensors and devices
- Messages and interactions
- Workflows and events
Developers represent these concepts using:
- Objects
- Data structures
- APIs
- Business logic
These representations are usually specific to the application being built.
For example:
- An e commerce platform may define products, orders, carts, and payments
- A healthcare system may model patients, appointments, and prescriptions
- A logistics platform may represent shipments, drivers, and delivery routes
This layer focuses on solving business problems in a way that reflects how users and organizations think about the domain.
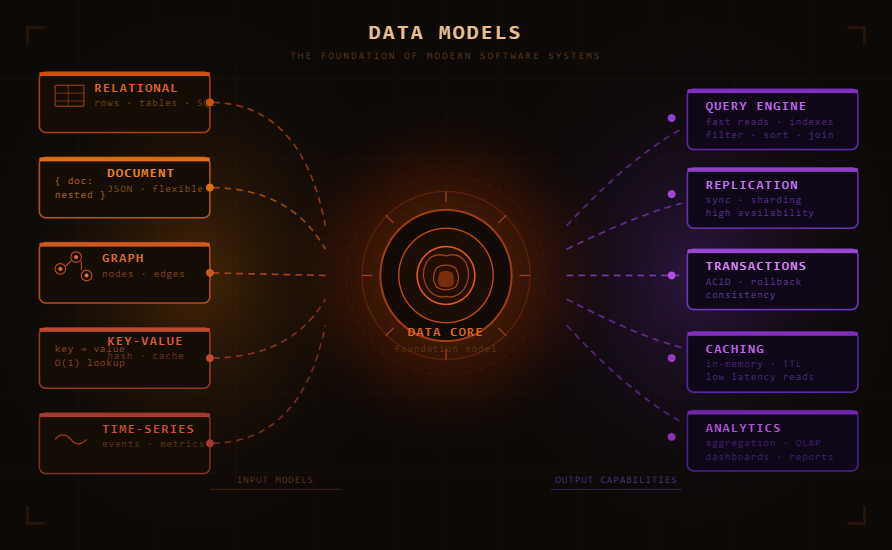
Layer 2: General Purpose Data Models
When applications need to persist data, those application specific structures must be expressed using more general purpose data models.
Common examples include:
- Relational tables
- JSON documents
- XML structures
- Graph models
- Key value stores
- Column oriented databases
This layer is critical because different data models support different kinds of workloads and access patterns.
Some data models are excellent for:
- Structured transactions
- Relationships and joins
- Data consistency
Others are optimized for:
- Flexible schemas
- Large scale distributed systems
- High throughput
- Complex interconnected data
The choice of data model has a profound effect on:
- Query performance
- Scalability
- Developer productivity
- System flexibility
- Future architectural decisions
Layer 3: Internal Database Representation
Below the logical data model lies the internal implementation of the database itself.
Database engineers decide how data is physically represented:
- In memory
- On disk
- Across networks
- Within distributed systems
At this level, data may be organized using:
- B trees
- Log structured storage
- Indexes
- Compression algorithms
- Replication systems
- Distributed partitions
These implementation details determine:
- Read and write performance
- Query efficiency
- Fault tolerance
- Scalability characteristics
- Storage optimization
Although application developers rarely interact directly with these low level mechanisms, they heavily influence system behavior.
For example:
- Some storage engines optimize for fast reads
- Others optimize for high write throughput
- Some prioritize consistency
- Others prioritize availability or partition tolerance
Understanding these tradeoffs helps engineers make better architectural decisions.
Layer 4: Hardware Level Representation
At the lowest level, hardware engineers represent information physically using:
- Electrical currents
- Magnetic fields
- Pulses of light
- Semiconductor states
Even digital information ultimately becomes a physical phenomenon managed by processors, storage devices, memory systems, and networking hardware.
Modern computing systems depend on multiple layers of abstraction to shield software developers from this underlying complexity.
Without these abstractions, building large software systems would be nearly impossible.
Why Data Models Matter So Much
Every data model embodies assumptions about how the data will be used.
As a result:
- Some operations become natural and efficient
- Others become difficult or inefficient
For example:
- Relational databases handle structured relationships and transactions very well
- Document databases excel with flexible and rapidly evolving schemas
- Graph databases are optimized for highly connected relationships
No single data model is ideal for every use case.
Choosing the wrong model can lead to:
- Poor query performance
- Scalability bottlenecks
- Complex application logic
- Increased operational overhead
- Difficult future migrations
This is why selecting an appropriate data model is one of the most important architectural decisions in software engineering.
Relational, Document, and Graph Models
Modern systems commonly use several major categories of data models.
Relational Model
Data is stored in tables consisting of rows and columns.
Strengths include:
- Strong consistency
- Structured schemas
- SQL querying
- Reliable transactions
- Mature tooling
Relational databases remain dominant for transactional systems and structured business applications.
Document Model
Data is stored as flexible documents, often using JSON like structures.
Strengths include:
- Flexible schemas
- Easier horizontal scaling
- Faster iteration for evolving applications
- Natural representation of nested data
Document databases are popular in web applications, content systems, and distributed cloud architectures.
Graph Model
Data is represented as nodes and relationships.
Strengths include:
- Modeling complex relationships
- Social networks
- Recommendation systems
- Fraud detection
- Knowledge graphs
Graph databases excel when relationships between entities are central to the application.
Abstractions Enable Collaboration
One of the most important benefits of layered data models is that they allow different groups of engineers to work independently while still collaborating effectively.
For example:
- Hardware engineers focus on physical infrastructure
- Database engineers optimize storage and query systems
- Backend developers design APIs and business logic
- Frontend developers build user experiences
Each layer hides unnecessary complexity from the layers above it.
These abstractions are essential for scaling modern software development across large engineering organizations.
The Challenge of Mastering Data Models
Data modeling is difficult because each model introduces its own:
- Concepts
- Constraints
- Performance tradeoffs
- Query patterns
- Operational characteristics
Entire books and academic fields exist around relational modeling, distributed databases, and graph theory because these systems are fundamentally complex.
Building software is already challenging even when using a single data model. Understanding how that model behaves internally adds another level of complexity.
However, because data models strongly influence what applications can and cannot do, engineers must understand them deeply enough to make informed architectural decisions.
The Relationship Between Data Models and System Design
Data models influence nearly every aspect of system architecture, including:
- Scalability strategies
- Query performance
- Data consistency
- Application flexibility
- Team productivity
- Operational complexity
A well chosen data model aligns naturally with the application’s access patterns and business requirements.
Poor alignment often forces developers to build increasingly complicated workarounds at the application layer.
Conclusion: Data Models Shape the Future of Software Systems
Data models are far more than storage formats they are foundational abstractions that shape how software systems are designed, built, and evolved.
Every layer of modern computing relies on abstraction, from physical hardware all the way to high level business logic. These abstractions allow engineers to manage complexity and collaborate effectively across massive systems.
The choice of data model has long term consequences for scalability, maintainability, flexibility, and performance. Different models solve different kinds of problems, and understanding their strengths and limitations is essential for building reliable and adaptable systems.
As software systems continue growing in complexity and scale, thoughtful data modeling becomes even more important. Engineers who understand data models deeply are better equipped to design systems that are not only functional today, but capable of evolving successfully in the future.










{kind=link}