




Figure1
Before designing systems that can scale effectively, it is essential to first understand the current load placed on those systems. Without a clear picture of how a system is being used today, it becomes nearly impossible to predict how it will behave under increased demand. This is why describing load is a critical first step in building reliable and scalable software systems.
What Is System Load?
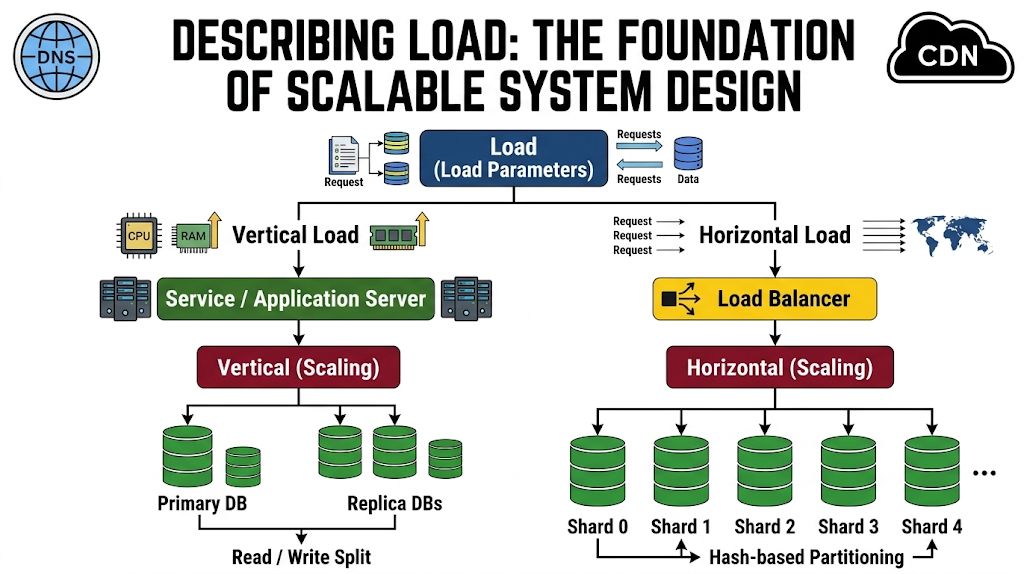
System load refers to the amount of work a system is required to handle at any given time. This workload can vary significantly depending on the type of application and its architecture. To make sense of this complexity, engineers define load parameters-specific metrics that capture how the system is being used.
These parameters are not universal; they depend heavily on the nature of the system. For example:
- A web server might measure load in requests per second
- A database system may focus on the ratio of read to write operations
- A chat application might track the number of active users simultaneously
- A caching system may monitor the cache hit rate
In some systems, the average load is the most important factor. In others, performance is dominated by edge cases, such as sudden spikes in traffic or unusually heavy users. Understanding which scenario applies is crucial for making the right design decisions.
Why Load Matters for Scalability
Once load is clearly defined, it becomes possible to ask meaningful scalability questions. For instance:
- What happens if traffic doubles?
- Can the system handle peak demand without slowing down?
- Where are the bottlenecks likely to appear?
Scalability is not just about handling growth-it is about handling growth gracefully. Without a proper understanding of load, scaling efforts can be misdirected, leading to wasted resources or system failures.
Case Study: Twitter’s Load Challenges
To better understand how load influences system design, consider a real-world example: Twitter. Based on publicly available data, Twitter handles two primary operations:
- Posting tweets: Approximately 4,600 requests per second on average, with peaks exceeding 12,000 requests per second
- Reading home timelines: Around 300,000 requests per second
At first glance, handling 12,000 write requests per second might seem like the primary challenge. However, Twitter’s real complexity lies elsewhere-in a concept known as fan-out.
Understanding Fan-Out in Distributed Systems
Fan-out refers to the process of delivering a single piece of data to multiple recipients. On Twitter, when a user posts a tweet, that tweet must be delivered to all of their followers. Since users often follow many accounts, and some accounts have millions of followers,this creates a massive multiplication effect.
This means the system’s load is not just determined by the number of tweets, but by how widely each tweet must be distributed.
Two Approaches to Handling Timeline Data
To manage this complexity, there are two primary architectural approaches:
Approach 1: Compute on Read
In this model:
- Tweets are stored in a global collection
- When a user requests their timeline:
- The system fetches tweets from all accounts they follow
- It then merges and sorts them in real time
Advantages:
- Simpler write operations
- Less duplication of data
Disadvantages:
- Expensive read operations
- Slower response times under heavy load
Approach 2: Compute on Write (Fan-Out)
In this approach:
- Each user has a precomputed “home timeline” (like a mailbox)
- When a tweet is posted:
- It is pushed to all followers’ timelines immediately
Advantages:
- Fast and efficient read operations
- Better user experience for timeline loading
Disadvantages:
- Expensive write operations
- High resource usage during tweet distribution
Why Twitter Switched Approaches
Initially, Twitter used the compute-on-read approach. However, as the platform grew, the system struggled to keep up with the high volume of timeline requests. To improve performance, Twitter transitioned to the compute-on-write model.
This shift made sense because:
- The number of timeline reads (300k/sec) far exceeded tweet writes (4.6k/sec)
- It was more efficient to do extra work during writes than during reads
However, this change introduced new challenges.
The Hidden Cost of Fan-Out
While the average tweet is delivered to about 75 followers, this number can vary dramatically. Some users-particularly celebrities- have tens of millions of followers.
This creates extreme cases where:
- A single tweet may trigger millions of write operations
- The system must distribute these updates within seconds
Handling such scenarios requires significant infrastructure and careful system design. Without optimization, these spikes can overwhelm the system.
The Hybrid Approach: Best of Both Worlds
To address these challenges, Twitter adopted a hybrid model:
- Most users’ tweets are handled using fan-out (compute-on-write)
- High-profile users with massive followings are treated differently:
- Their tweets are fetched dynamically when timelines are read (compute-on-read)
This approach balances efficiency and scalability by:
- Reducing the cost of extreme fan-out scenarios
- Maintaining fast performance for the majority of users
Key Takeaways for System Design
The Twitter example highlights several important principles:
- Load is multi-dimensional: It’s not just about request volume, but also data relationships and distribution patterns
- Averages can be misleading: Edge cases often define system limits
- Architecture must evolve: What works at small scale may fail at large scale
- Hybrid solutions are powerful: Combining approaches can provide better performance than relying on a single strategy
Conclusion: Think in Terms of Load, Not Just Scale
Describing load is the foundation of scalable system design. Before attempting to scale a system, engineers must understand how it behaves under current conditions and identify the factors that drive its workload.
By defining clear load parameters and analyzing real-world usage patterns, organizations can make informed decisions about architecture, resource allocation, and optimization strategies.
Ultimately, scalability is not just about handling more users or more data; it is about understanding the nature of the load and designing systems that can adapt to it efficiently and reliably.