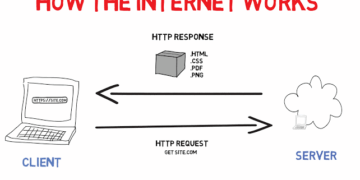






Figure1
In modern software engineering, building an application is only the beginning of the journey. Once a system is deployed into production, its long-term success depends heavily on how effectively it can be operated, monitored, maintained, and supported over time. This is where the concept of operability becomes essential.
Operability refers to how easy it is for operations teams to manage and maintain a system efficiently in real-world environments. A highly operable system allows teams to identify issues quickly, recover from failures effectively, automate repetitive tasks, and maintain stability even as the system evolves.
There is a well-known idea in software engineering that highlights the importance of operations:
“Good operations can often work around the limitations of bad software, but even good software cannot run reliably with poor operations.”
This principle emphasizes a critical reality: software reliability depends not only on code quality but also on the people and processes responsible for running the system.
Why Operations Teams Matter
Operations teams play a foundational role in ensuring that software systems remain stable, secure, and available. Their responsibilities extend far beyond simply “keeping servers running.”
A strong operations team typically handles:
- Monitoring system health and availability
- Detecting and responding to incidents
- Troubleshooting failures and performance degradation
- Managing deployments and infrastructure updates
- Applying security patches and compliance updates
- Planning for future growth and capacity needs
- Maintaining stability during system changes
- Preserving institutional knowledge about the system
Without effective operations, even technically advanced systems can become unreliable, difficult to manage, and prone to outages.
The Human Element in Modern Operations
Although automation has transformed infrastructure management, operations still rely heavily on human expertise. Automated systems do not design themselves-they require engineers to:
- Configure workflows
- Define monitoring thresholds
- Build deployment pipelines
- Investigate anomalies
- Respond to unexpected failures
Automation reduces repetitive work, but humans remain responsible for ensuring that automation behaves correctly and adapts to changing conditions.
This makes operability not just a technical challenge, but also an organizational and human-centered one.
Core Responsibilities of High-Performing Operations Teams
1. Monitoring and Incident Response
One of the most critical responsibilities of operations teams is continuously monitoring system health.
This includes:
- Detecting outages or abnormal behavior
- Monitoring performance metrics and resource usage
- Receiving alerts for failures or threshold violations
- Restoring service as quickly as possible when issues occur
Strong monitoring systems provide visibility into:
- CPU and memory usage
- Network activity
- Database performance
- Error rates and latency
- Application logs and traces
Without visibility, diagnosing production problems becomes extremely difficult.
2. Problem Diagnosis and Root Cause Analysis
When failures occur, operations teams must identify the root cause quickly and accurately.
This often involves:
- Investigating logs and metrics
- Analyzing infrastructure dependencies
- Identifying performance bottlenecks
- Coordinating across engineering teams
Effective systems are designed to support troubleshooting through observability, logging, and traceability.
3. Capacity Planning and Future Readiness
Operations teams are responsible for anticipating future demands before they become critical issues.
This includes:
- Forecasting infrastructure growth
- Monitoring usage trends
- Planning hardware or cloud resource expansion
- Preventing overload during traffic spikes
Capacity planning is essential for maintaining performance and avoiding outages caused by unexpected growth.
4. Deployment and Configuration Management
Reliable deployments are a cornerstone of operability.
Operations teams establish:
- Standardized deployment processes
- Infrastructure-as-code practices
- Environment consistency across systems
- Rollback procedures for failed deployments
Good deployment practices reduce downtime, minimize human error, and improve confidence during releases.
5. Security Maintenance
As systems evolve, maintaining security becomes increasingly important.
Operations teams help:
- Apply security patches
- Monitor vulnerabilities
- Manage access controls
- Maintain compliance requirements
- Secure infrastructure and configurations
Security is not a one-time setup-it is an ongoing operational responsibility.
Characteristics of Highly Operable Systems
A system designed with operability in mind should make routine operational tasks straightforward and predictable.
Key characteristics include:
Visibility and Observability
Systems should expose meaningful runtime information through:
- Metrics dashboards
- Centralized logging
- Distributed tracing
- Real-time alerts
This visibility enables faster diagnosis and proactive issue resolution.
Automation-Friendly Design
Modern systems should integrate easily with automation tools for:
- Deployments
- Scaling
- Monitoring
- Recovery workflows
Automation reduces repetitive work and allows teams to focus on higher-value activities.
Resilience and Independence from Individual Machines
Highly operable systems avoid relying on single machines or fragile infrastructure components.
This allows:
- Maintenance without downtime
- Easier hardware replacement
- Improved fault tolerance
- Better system availability
Distributed and redundant architectures often improve operational flexibility.
Clear Documentation and Predictability
Operational tasks become significantly easier when systems are:
- Well-documented
- Consistent in behavior
- Easy to reason about
Engineers should be able to predict system outcomes confidently:
“If I perform action X, behavior Y should occur.”
Predictability reduces operational surprises and increases confidence during changes.
Balanced Automation and Manual Control
Self-healing systems can automatically recover from common failures, but operations teams should still retain manual control when necessary.
Good operability balances:
- Automation for efficiency
- Human oversight for flexibility and safety
Too much automation without visibility or control can create hidden risks.
The Relationship Between Operability and Reliability
Operability and reliability are deeply connected. Systems that are difficult to monitor or manage are more likely to experience prolonged outages and operational instability.
Strong operability improves:
- Incident response times
- Recovery speed
- System uptime
- Team productivity
- User trust
In many cases, operational excellence becomes a competitive advantage.
Conclusion: Designing Systems for the People Who Run Them
Operability is often overlooked during software design, yet it plays a defining role in the long-term success of a system. A technically sophisticated application can still fail if it is difficult to monitor, maintain, or operate in production environments.
Designing for operability means recognizing that software systems are not static products-they are living systems that require ongoing care and attention. Operations teams are responsible for ensuring stability, security, performance, and continuity, often under high-pressure conditions.
Systems that prioritize operability empower teams to work proactively rather than reactively. They reduce operational friction, minimize downtime, and create environments where engineers can focus on improvement rather than constant firefighting.
As systems grow more distributed and complex, operability becomes even more important. Clear monitoring, automation, documentation, resilience, and predictable behavior are no longer optional-they are essential foundations for sustainable software systems.
Organizations that invest in operability are not only improving technical reliability; they are also improving collaboration, reducing risk, and building systems that can adapt and thrive over time.









{kind=link}