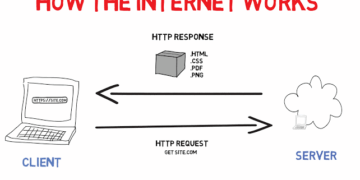






Figure 2.3
At the most fundamental level, every database system is designed to solve two core problems: reliably storing data and efficiently retrieving that data whenever it is needed. This remains true regardless of whether the system is a relational database, document database, graph database, or a distributed cloud platform. These two responsibilities form the foundation of all database design.
For application developers, databases often appear simple on the surface. Data is inserted, updated, queried, and deleted through APIs or query languages such as SQL. However, beneath this abstraction layer lies one of the most critical components of any database system: the storage engine.
The storage engine determines how data is physically written to disk, how it is organized in memory, how indexes are maintained, and how information is retrieved and optimized across different workloads. While developers rarely implement storage engines directly, understanding their behavior is essential when designing scalable, reliable, and high-performance systems.
Why Storage Engines Matter
Choosing a database is not simply a matter of selecting a popular technology. Different databases are built on different storage engine architectures, and these design choices directly influence system behavior.
Key areas affected include performance, scalability, reliability, query speed, write efficiency, resource utilization, and operational complexity.
A storage engine optimized for one type of workload may perform poorly under another.
For example, systems optimized for high-speed transactional processing may struggle with large-scale analytical queries. Similarly, analytics-focused engines may not perform efficiently under heavy real-time write workloads. In addition, some storage engines prioritize consistency, while others emphasize throughput and availability.
This makes storage internals a critical area of understanding for engineers who want to make informed architectural decisions rather than treating databases as black boxes.
Databases Are More Than Query Languages
When discussing databases, developers often focus on interfaces such as SQL, JSON, graph queries, APIs, and ORM frameworks. While these tools are important, they only represent how applications interact with the database.
The more complex engineering challenges exist internally.
Key internal concerns include how data is organized on disk, how indexing is implemented for fast retrieval, how disk operations are minimized, how crash recovery is handled, how systems scale under load, and how read and write operations are balanced.
These responsibilities are handled primarily by the storage engine, and the same database interface can behave very differently depending on the underlying implementation.
Transactional vs Analytical Workloads
A major concept in database engineering is the distinction between transactional (OLTP) and analytical (OLAP) workloads.
Transactional systems are designed for high-frequency, small-scale operations in real time. Examples include banking systems, e-commerce platforms, payment processing systems, authentication services, reservation systems, and social media interactions.
These systems prioritize low latency, high concurrency, fast writes, data consistency, and system reliability. In many cases, they process millions of small operations per second while maintaining strict accuracy.
Analytical systems, on the other hand, are optimized for processing large volumes of data. These include business intelligence dashboards, data warehouses, reporting platforms, machine learning pipelines, and large-scale trend analysis systems.
They prioritize large dataset scans, complex aggregations, query optimization, compression efficiency, and high read throughput rather than low-latency writes.
Understanding this distinction is essential, as the optimal storage engine for transactional systems is often not suitable for analytical workloads.
Two Major Families of Storage Engines
Modern database systems are generally built around two primary storage engine architectures:
Log-structured storage engines
Page-oriented storage engines
Each approach represents a different strategy for managing how data is stored and retrieved.
Log-Structured Storage Engines
Log-structured storage engines are designed primarily for high write throughput. Instead of modifying data directly on disk, changes are appended sequentially to a log structure.
This approach leverages the efficiency of sequential disk writes, which are significantly faster than random disk access, especially on traditional storage systems.
Key advantages include high write performance, efficient sequential I/O, reduced disk seek overhead, and strong support for streaming or continuous data ingestion.
These systems are commonly used in distributed databases, event-driven architectures, streaming platforms, and large-scale NoSQL systems.
However, they also introduce challenges such as background compaction, increased read complexity, storage fragmentation, and higher system maintenance overhead.
Page-Oriented Storage Engines and B-Trees
Page-oriented storage engines take a different approach by organizing data into fixed-size pages and updating records within those pages.
A central structure in this model is the B-Tree, which is widely used for indexing and data retrieval.
B-Trees are effective because they support fast lookups, maintain sorted data, handle large datasets efficiently, minimize disk reads, and enable efficient range queries.
Relational database systems such as PostgreSQL, MySQL, and Microsoft SQL Server are commonly built on B-Tree-based storage engines.
This architecture is particularly well-suited for fast random reads, structured queries, indexed access patterns, and strong transactional consistency.
While page-oriented systems may not match the write throughput of log-structured designs under extreme workloads, they remain highly reliable and versatile for general-purpose applications.
Why Developers Should Understand Storage Internals
Modern cloud platforms and managed database services make it easy to deploy systems quickly. However, performance and scalability challenges often emerge when developers do not understand how storage engines behave under real-world workloads.
Poor design choices can lead to slow query performance, high infrastructure costs, increased latency, data bottlenecks, and system instability.
A solid understanding of storage internals enables engineers to design better architectures, optimize workloads, select appropriate databases, predict scaling behavior, improve system reliability, and reduce operational waste.
Even without implementing storage engines directly, this knowledge significantly improves system design decisions.
The Foundation of Modern Data Systems
Storage engines form the invisible foundation beneath modern applications. Every major digital system whether social platforms, financial systems, cloud services, or analytics pipelines depends on efficient storage and retrieval mechanisms operating behind the scenes.
As software systems continue to scale globally, storage engine design plays a critical role in balancing performance, reliability, scalability, cost efficiency, and maintainability.
A deeper understanding of these systems equips engineers to build applications that remain efficient, resilient, and adaptable as they evolve in complexity and scale.
For a deeper understanding of relational and document-based systems, see:
data-models-the-foundation-of-modern-software-system
For more insights into software engineering and distributed systems, visit https chiidtech.com










{kind=link}