




Figure1
Once you understand how to describe system load and measure performance, the next step is tackling scalability in a practical way. The key question becomes: how do we maintain strong performance as demand increases?
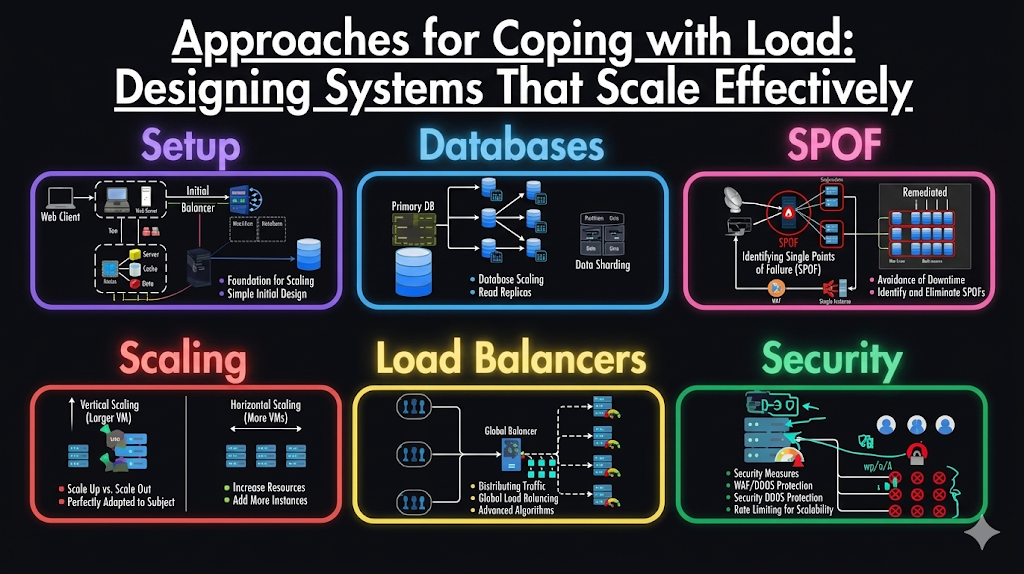
Scaling is not a one-time decision.It is an ongoing process. As systems grow, architectures that once worked efficiently may quickly become inadequate. In fact, a system designed for today’s workload may completely fail under ten times the load. For fast-growing applications, this often means rethinking the architecture at every significant growth stage.
Scaling Up vs Scaling Out: Two Core Approaches
When handling increased load, engineers typically consider two primary strategies:
- Scaling Up (Vertical Scaling)
This involves upgrading to a more powerful machine more CPU, more memory, and better hardware. - Scaling Out (Horizontal Scaling)
This distributes the workload across multiple smaller machines, often referred to as a shared-nothing architecture.
Scaling up is simpler because everything runs on a single system, reducing complexity. However, high-end machines can be extremely expensive and have physical limits.
Scaling out, on the other hand, offers flexibility and resilience. By distributing work across multiple nodes, systems can handle much larger workloads. However, this approach introduces complexity, especially when coordinating tasks across machines.
In reality, most well-designed systems use a hybrid approach combining a few powerful machines with distributed components to balance cost, performance, and simplicity.
Elastic vs Manual Scaling: Choosing the Right Strategy
Another important consideration is how scaling is managed:
- Elastic Scaling
Systems automatically adjust resources based on demand. When load increases, new resources are added dynamically. - Manual Scaling
Engineers monitor system performance and decide when to add resources.
Elastic systems are particularly useful in environments with unpredictable traffic patterns. However, they can introduce operational complexity and unexpected behavior if not carefully managed.
Manual scaling, while less flexible, is often simpler and provides more control. Many organizations prefer this approach for stable workloads where demand is easier to predict.
The Challenge of Scaling Stateful Systems
Scaling stateless services, such as web servers, is relatively straightforward. Since they do not store persistent data, requests can be routed to any available machine.
However, scaling stateful systems, such as databases, is much more complex. Moving from a single-node database to a distributed system introduces challenges like:
- Data consistency
- Replication and synchronization
- Fault tolerance
- Increased operational overhead
For a long time, the common approach was to keep databases on a single node (scale up) for as long as possible. Only when cost or availability requirements became too significant would teams transition to distributed systems.
Today, with advancements in distributed technologies, this mindset is evolving. Distributed data systems are becoming more accessible and may soon become the default even for applications that do not handle massive scale.
There Is No “One-Size-Fits-All” Architecture
A critical principle in system design is that there is no universal scalable architecture. Every system must be designed based on its unique requirements.
Factors that influence architecture include:
- Volume of read operations
- Volume of write operations
- Size and complexity of data
- Response time requirements
- Access patterns
- Traffic distribution
For example:
- A system handling 100,000 small requests per second requires a very different design from one handling a few large requests per minute, even if total data throughput is similar.
This highlights the importance of understanding your system’s load characteristics before making architectural decisions.
Designing Around Real-World Assumptions
Scalable systems are built based on assumptions about how they will be used:
- Which operations are frequent?
- Which are rare?
- Where are the bottlenecks likely to occur?
These assumptions guide architectural decisions. However, if they turn out to be incorrect, the system may become inefficient or difficult to scale.
In early-stage products or startups, it is often more important to prioritize speed of development and iteration over scalability. Over-engineering for a hypothetical future can waste time and resources.
Building Blocks of Scalable Systems
Although every scalable system is unique, most are built using common patterns and components, such as:
- Load balancers
- Distributed databases
- Caching layers
- Message queues
- Microservices architectures
These building blocks can be combined in different ways to meet specific requirements. The challenge lies in choosing the right combination based on your system’s needs.
Conclusion: Scaling Is a Continuous Journey
Coping with load is not about finding a perfect architecture.It is about continuously adapting your system as it grows.
Key takeaways include:
- Systems must evolve as load increases
- Scaling up and scaling out each have trade-offs
- Stateless systems are easier to scale than stateful ones
- There is no universal solution-architecture must match the problem
- Early-stage systems should prioritize flexibility over premature scaling
successful scalability comes from understanding your system, making informed trade-offs, and being willing to adapt as conditions change.